FunASR希望在语音识别的学术研究和工业应用之间架起一座桥梁。 通过发布工业级语音识别模型的训练和微调,研究人员和开发人员可以更方便地进行语音识别模型的研究和生产,并推动语音识别生态的发展。 让语音识别更有趣!
目前可以用cpu来部署,实测准确率还可以

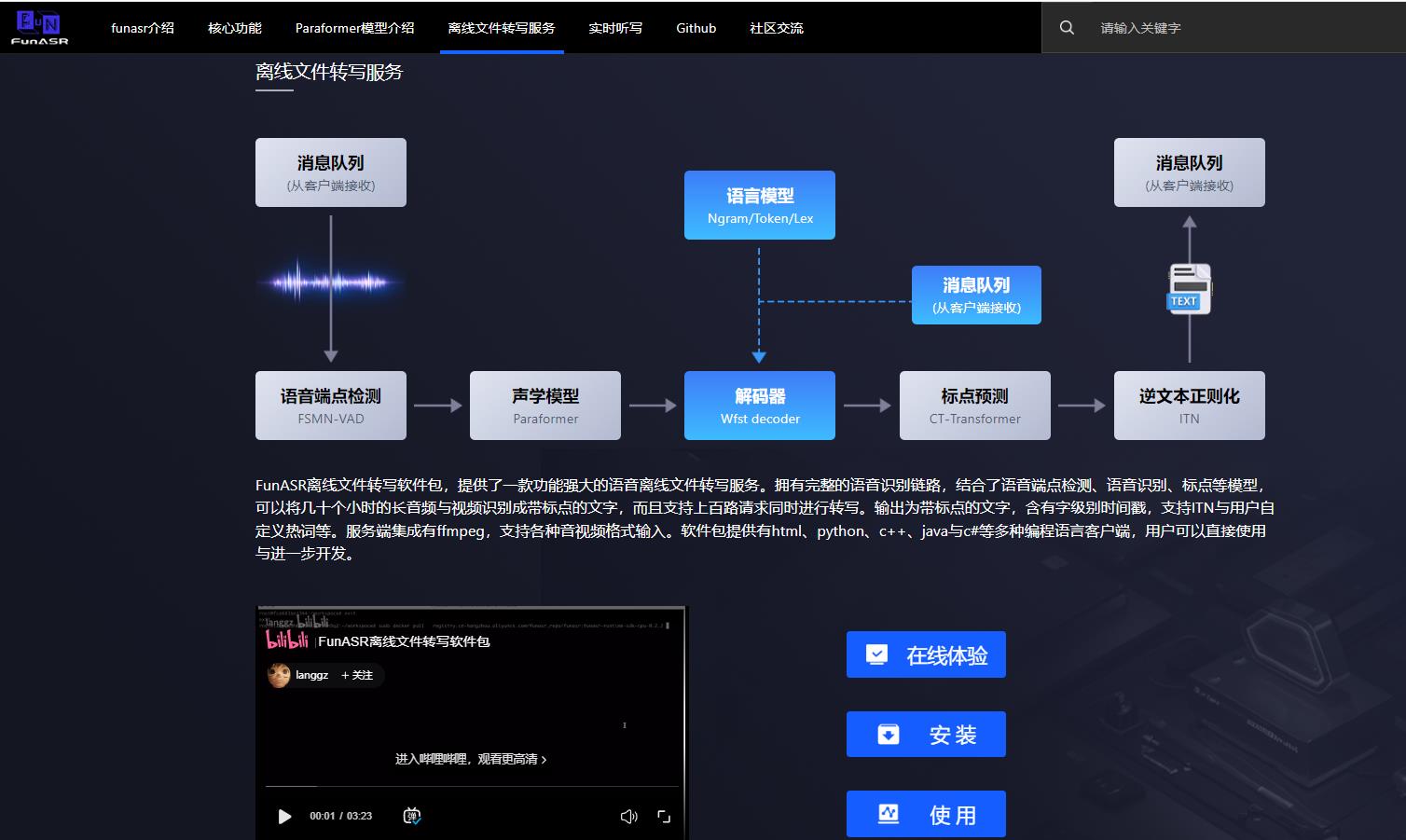
- FunASR是一个基础语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。FunASR提供了便捷的脚本和教程,支持预训练好的模型的推理与微调。
- 我们在ModelScope与huggingface上发布了大量开源数据集或者海量工业数据训练的模型,可以通过我们的模型仓库了解模型的详细信息。代表性的Paraformer非自回归端到端语音识别模型具有高精度、高效率、便捷部署的优点,支持快速构建语音识别服务,详细信息可以阅读(服务部署文档)。
最新动态
- 2024/01/25: 中文离线文件转写服务 4.2、英文离线文件转写服务 1.3,优化vad数据处理方式,大幅降低峰值内存占用,内存泄漏优化;中文实时语音听写服务 1.7 发布,客户端优化;详细信息参阅(部署文档)
- 2024/01/09: funasr社区软件包windows 2.0版本发布,支持软件包中文离线文件转写4.1、英文离线文件转写1.2、中文实时听写服务1.6的最新功能,详细信息参阅(FunASR社区软件包windows版本)网址https://www.modelscope.cn/models/iic/funasr-runtime-win-cpu-x64/summary
- 2024/01/03: 中文离线文件转写服务 4.0 发布,新增支持8k模型、优化时间戳不匹配问题及增加句子级别时间戳、优化英文单词fst热词效果、支持自动化配置线程参数,同时修复已知的crash问题及内存泄漏问题,详细信息参阅(部署文档)
- 2024/01/03: 中文实时语音听写服务 1.6 发布,2pass-offline模式支持Ngram语言模型解码、wfst热词,同时修复已知的crash问题及内存泄漏问题,详细信息参阅(部署文档)
- 2024/01/03: 英文离线文件转写服务 1.2 发布,修复已知的crash问题及内存泄漏问题,详细信息参阅(部署文档)
- 2023/12/04: funasr社区软件包windows 1.0版本发布,支持中文离线文件转写、英文离线文件转写、中文实时听写服务,详细信息参阅(FunASR社区软件包windows版本)
- 2023/11/08:中文离线文件转写服务3.0 CPU版本发布,新增标点大模型、Ngram语言模型与wfst热词,详细信息参阅(部署文档)
- 2023/10/17: 英文离线文件转写服务一键部署的CPU版本发布,详细信息参阅(部署文档)
- 2023/10/13: SlideSpeech: 一个大规模的多模态音视频语料库,主要是在线会议或者在线课程场景,包含了大量与发言人讲话实时同步的幻灯片。
- 2023.10.10: Paraformer-long-Spk模型发布,支持在长语音识别的基础上获取每句话的说话人标签。
- 2023.10.07: FunCodec: FunCodec提供开源模型和训练工具,可以用于音频离散编码,以及基于离散编码的语音识别、语音合成等任务。
- 2023.09.01: 中文离线文件转写服务2.0 CPU版本发布,新增ffmpeg、时间戳与热词模型支持,详细信息参阅(部署文档)
- 2023.08.07: 中文实时语音听写服务一键部署的CPU版本发布,详细信息参阅(部署文档)
- 2023.07.17: BAT一种低延迟低内存消耗的RNN-T模型发布,详细信息参阅(BAT)
- 2023.06.26: ASRU2023 多通道多方会议转录挑战赛2.0完成竞赛结果公布,详细信息参阅(M2MeT2.0)
安装教程
FunASR安装教程请阅读(Installation)
模型仓库
FunASR开源了大量在工业数据上预训练模型,您可以在模型许可协议下自由使用、复制、修改和分享FunASR模型,下面列举代表性的模型,更多模型请参考模型仓库。
(注:?表示Huggingface模型仓库链接,⭐表示ModelScope模型仓库链接)
| 模型名字 | 任务详情 | 训练数据 | 参数量 |
|---|---|---|---|
| paraformer-zh (⭐ ? ) | 语音识别,带时间戳输出,非实时 | 60000小时,中文 | 220M |
| paraformer-zh-streaming ( ⭐ ? ) | 语音识别,实时 | 60000小时,中文 | 220M |
| paraformer-en ( ⭐ ? ) | 语音识别,非实时 | 50000小时,英文 | 220M |
| conformer-en ( ⭐ ? ) | 语音识别,非实时 | 50000小时,英文 | 220M |
| ct-punc ( ⭐ ? ) | 标点恢复 | 100M,中文与英文 | 1.1G |
| fsmn-vad ( ⭐ ? ) | 语音端点检测,实时 | 5000小时,中文与英文 | 0.4M |
| fa-zh ( ⭐ ? ) | 字级别时间戳预测 | 50000小时,中文 | 38M |
| cam++ ( ⭐ ? ) | 说话人确认/分割 | 5000小时 | 7.2M |
相关导航






暂无评论...