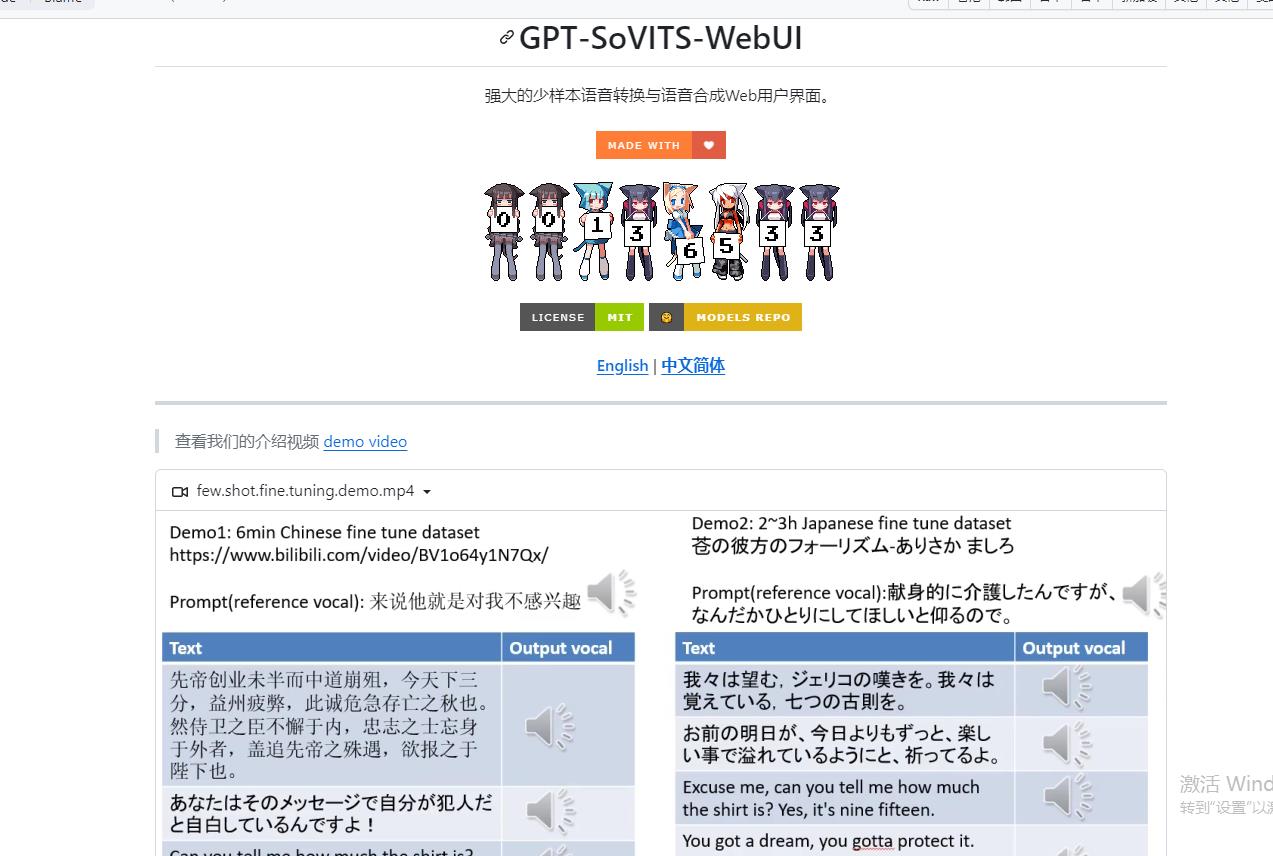
强大的少样本语音转换与语音合成Web用户界面。
功能:
零样本文本到语音(TTS): 输入5秒的声音样本,即刻体验文本到语音转换。
少样本TTS: 仅需1分钟的训练数据即可微调模型,提升声音相似度和真实感。
跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
WebUI工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和GPT/SoVITS模型。
介绍视频https://www.bilibili.com/video/BV12g4y1m7Uw/ 来自B站up主:花儿不哭
相关导航





暂无评论...