最近几个月,我们专注探索如何构建一个真正「卓越」的模型,并在此过程中不断提升开发者的使用体验。在农历新年即将到来之际,我们满怀欣喜地与大家分享新一代通义千问模型: Qwen1.5。

在此次Qwen1.5版本中,我们开源了包括0.5B、1.8B、4B、7B、14B和72B在内的6个不同规模的Base和Chat模型,并一如既往地放出了各规模对应的量化模型。此次更新中,我们不仅像之前一样提供Int4和Int8的GPTQ模型,还提供了AWQ以及GGUF量化模型。为了提升开发者体验,我们将Qwen1.5的代码正式合并到Hugging Face transformers代码库中,所以现在可以直接使用 transformers>=4.37.0 原生代码,而无需指定 trust_remote_code 选项即可进行开发。
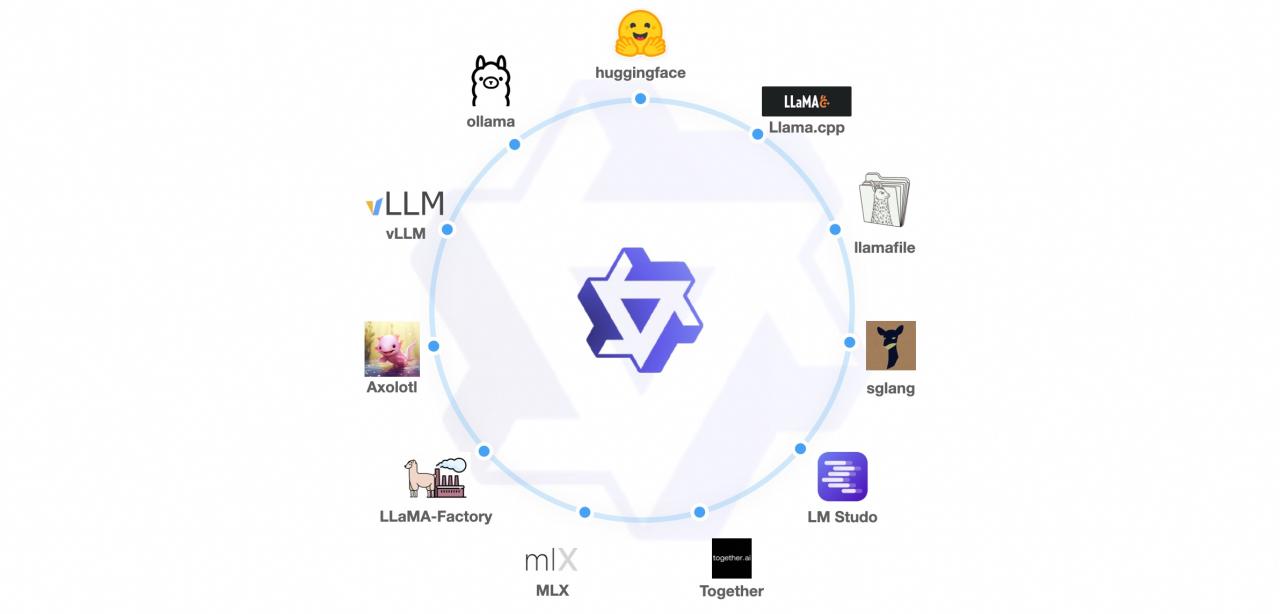
我们已经与vLLM、SGLang(用于部署)、AutoAWQ、AutoGPTQ(用于量化)、Axolotl、LLaMA-Factory(用于微调)以及llama.cpp(用于本地 LLM 推理)等框架合作,所有这些框架现在都支持 Qwen1.5。Qwen1.5 系列可在 Ollama 和 LMStudio 等平台上使用。此外,API 服务不仅在 DashScope 上提供,还在 together.ai 上提供,全球都可访问。请访问here开始使用,我们建议您试用Qwen1.5-72B-chat。
相较于以往版本,本次更新我们着重提升Chat模型与人类偏好的对齐程度,并且显著增强了模型的多语言处理能力。在序列长度方面,所有规模模型均已实现 32768 个 tokens 的上下文长度范围支持。同时,预训练 Base 模型的质量也有关键优化,有望在微调过程中为您带来更佳体验。这次迭代是我们朝向「卓越」模型目标所迈进一个坚实的步伐。