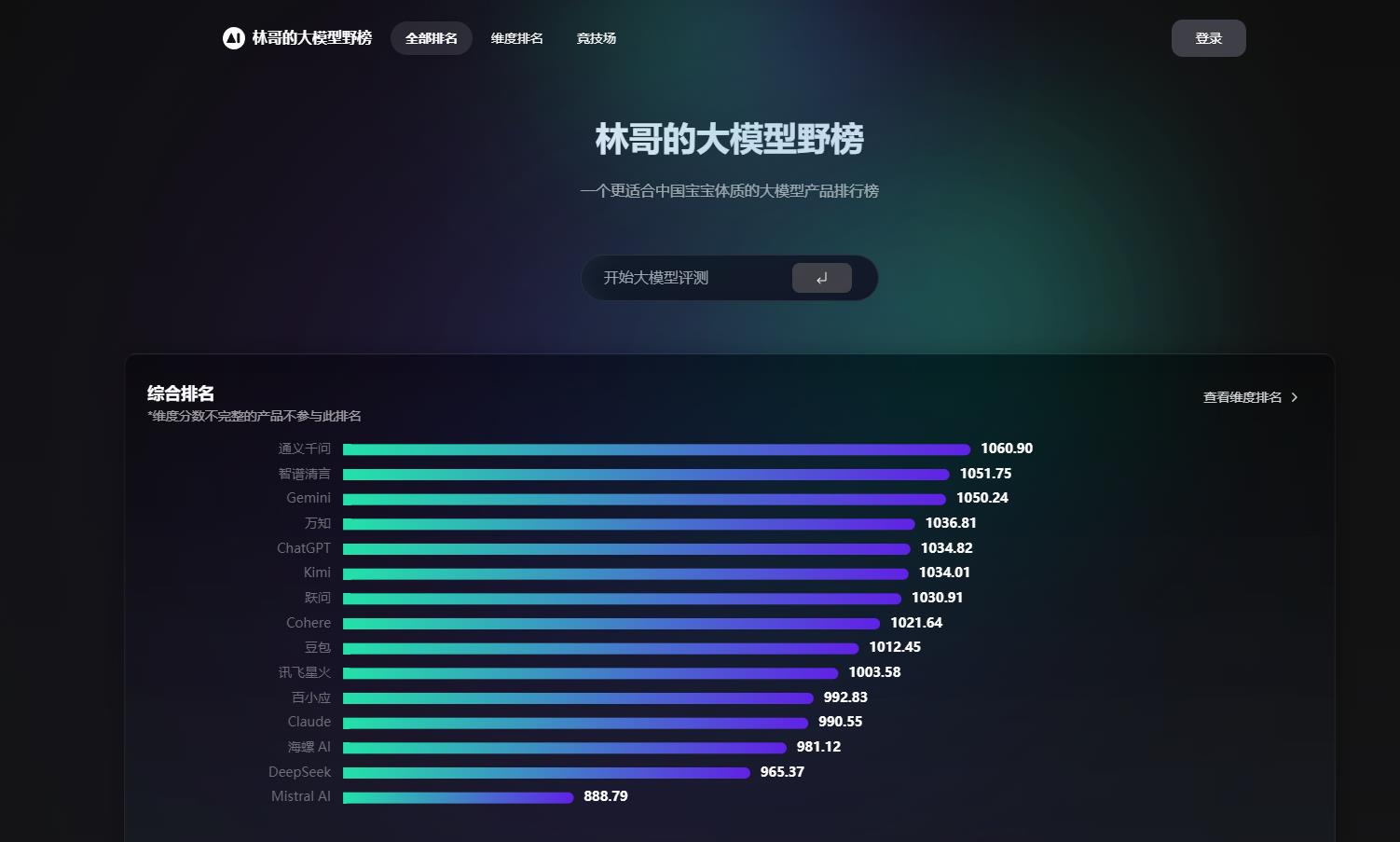
这两年各种号称能超越 OpenAI 的大模型层出不穷。为找出最好用的大模型,作者搭建了一个大模型竞技场的网站,并免费开放,希望借助大家的力量做出更适合中国的第三方大模型产品排行榜。目前网站已开始运行,前期模型可能排名不太稳定
“大模型竞技场”的灵感源于LMSYS提出来的Chatbot Arena,聊天机器人竞技场。
测试原理是引入了 ELO 机制,让模型与模型对抗。具体为让两个大模型同时回答用户的一个问题,再由用户选择哪个模型回答得更好。用户出题、用户打分,题目灵活多变,评判标准更接近人的真实感受。
随后还介绍了大模型竞技场中的自动化决定和防作弊功能。通过小AI统计模型在不同维度下的表现,并减少简单重复性问题的影响。同时采用连坐方式防止模型泄露关键信息,保证竞技场的公平性。用户可通过网站进行大模型对抗赛和查看排名信息。
介绍视频:https://www.bilibili.com/video/BV1RS421972P/