SuperBench是什么
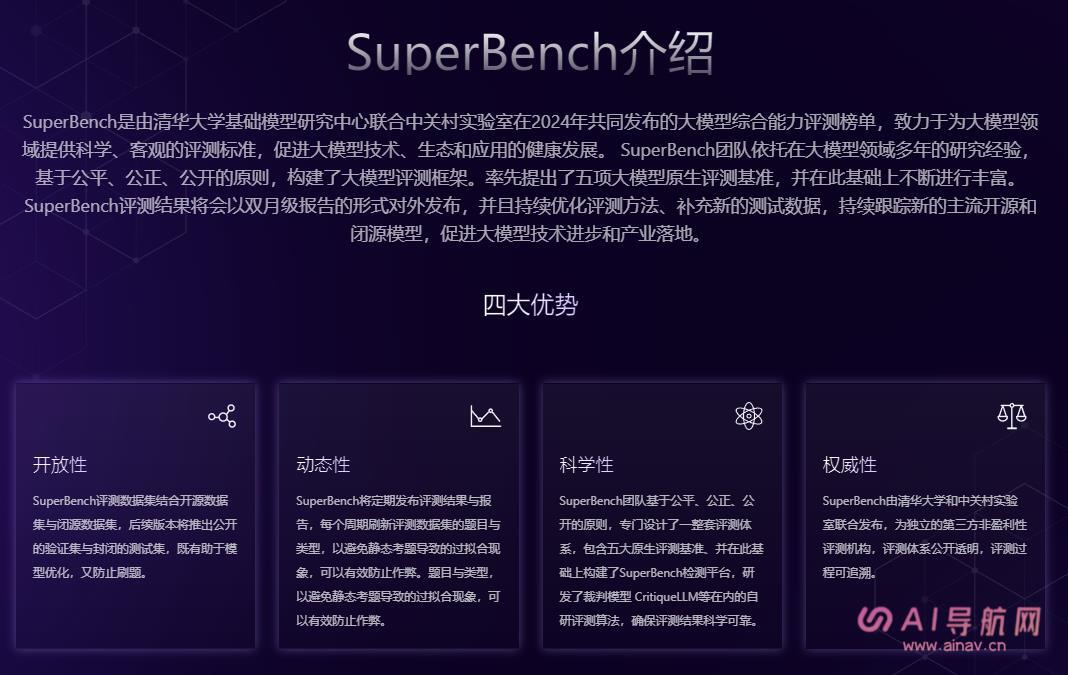
SuperBench 是由清华大学基础模型研究中心联合中关村实验室在 2024 年共同发布的大模型综合能力评测榜单,致力于为大模型领域提供科学、客观的评测标准,促进大模型技术、生态和应用的健康发展。
其官网首页显示 “致力于打造一个公平、公正、公开、系统的评测体系,以推动国内大模型研究与应用的进步”,并提供了 “加入评测” 和 “最新榜单” 等按钮,方便用户参与和查看最新信息。

SuperBench 的主要功能
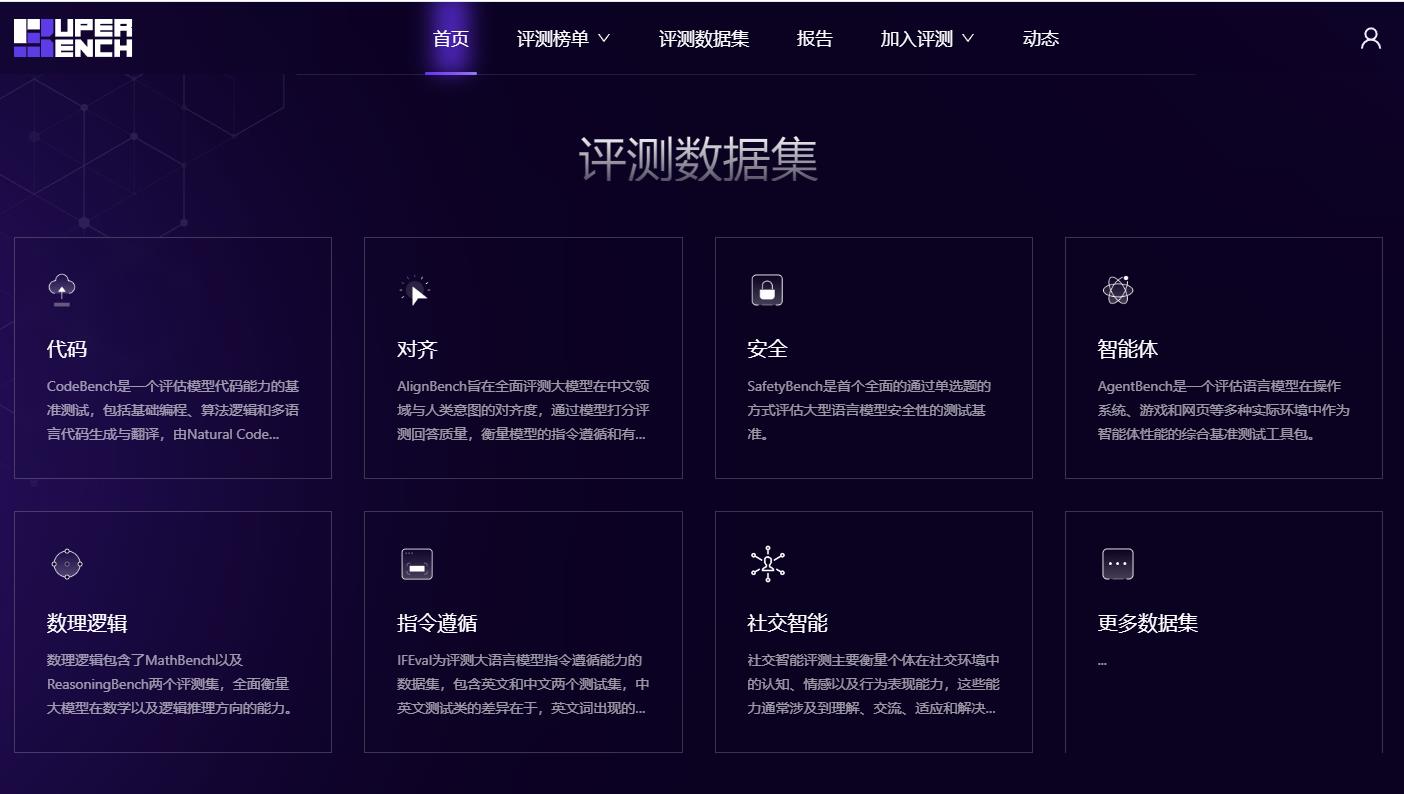
- 评测数据集:
- 代码评测:CodeBench 是一个评估模型代码能力的基准测试,包括基础编程、算法逻辑和多语言代码生成与翻译,由 Natural Code Bench、Humaneval 和 Mbpp 三大数据集组成,模拟真实编程场景并考核多语言环境下的代码理解和生成技巧。例如 Natural Code Bench,本类别旨在自动化考察真实场景下模型根据用户需求生成代码的能力,所有问题都从用户在线上服务中的提问筛选得来,问题的风格和格式更加多样,涵盖了算法、数学逻辑、基础编程知识、库函数运用、现实任务求解等,可以简单分为算法类和功能需求类两类,包含 java 和 python 两类语言。每个问题都对应 10 个由 gpt4 自动生成的测试样例,9 个用于测试生成代码的功能正确性,剩下 1 个用于代码对齐。
- 对齐评测:AlignBench 旨在全面评测大模型在中文领域与人类意图的对齐度,通过模型打分评测回答质量,衡量模型的指令遵循和有用性。它包括8个维度,如基本任务和专业能力,使用真实高难度问题,并有高质量参考答案。优秀表现要求模型具有全面能力、指令理解和生成有帮助的答案。
- 安全评测:SafetyBench 是首个全面的通过单选题的方式评估大型语言模型安全性的测试基准。
- 智能体评测:AgentBench 是一个评估语言模型在操作系统、游戏和网页等多种实际环境中作为智能体性能的综合基准测试工具包。
- 数理逻辑评测:包含了 MathBench 以及 ReasoningBench 两个评测集,全面衡量大模型在数学以及逻辑推理方向的能力。
- 指令遵循评测:IFEval 为评测大语言模型指令遵循能力的数据集,包含英文和中文两个测试集,中英文测试类的差异在于,英文词出现的次数和英文大小写的限制。评测方法为通过给定相应的提示指令,通过规则的方式验证模型回复是否遵循指令。规则包含关键字限制、语言类别限制、长度限制、内容检测、内容格式、组合回复、开头结尾限制、标点符号限制等。
- 社交智能评测:主要衡量个体在社交环境中的认知、情感以及行为表现能力,这些能力通常涉及到理解、交流、适应和解决人际互动中的问题。本次评测主要衡量大语言模型的心智(Theory-of-Mind)和情商(Emotional Intelligence)水平,使用 ToMBench 和 EmoBench 作为评测集。
- 数学能力:MathBench 是首个全面分析数学领域发展历程,科学划分数学评估子维度,且人工构造相应子维度学科数据的测试基准,可用于精准评估大语言模型的数学能力。MathBench 以计算题为主,包含初等数学、近代数学、现代数学四个子模块,全面评估大语言模型在各个数学维度的能力。
- 逻辑推理能力:通过单项选择题(ReasoningBench)、判断题(ReasoningBench)以及具有唯一答案的开放式问题(LogicGame)等多种形式,综合评估大模型逻辑推理能力的基准测试。该测试的所有数据均为自主生成,并经过设计以实现难度分级。
- 评测榜单:
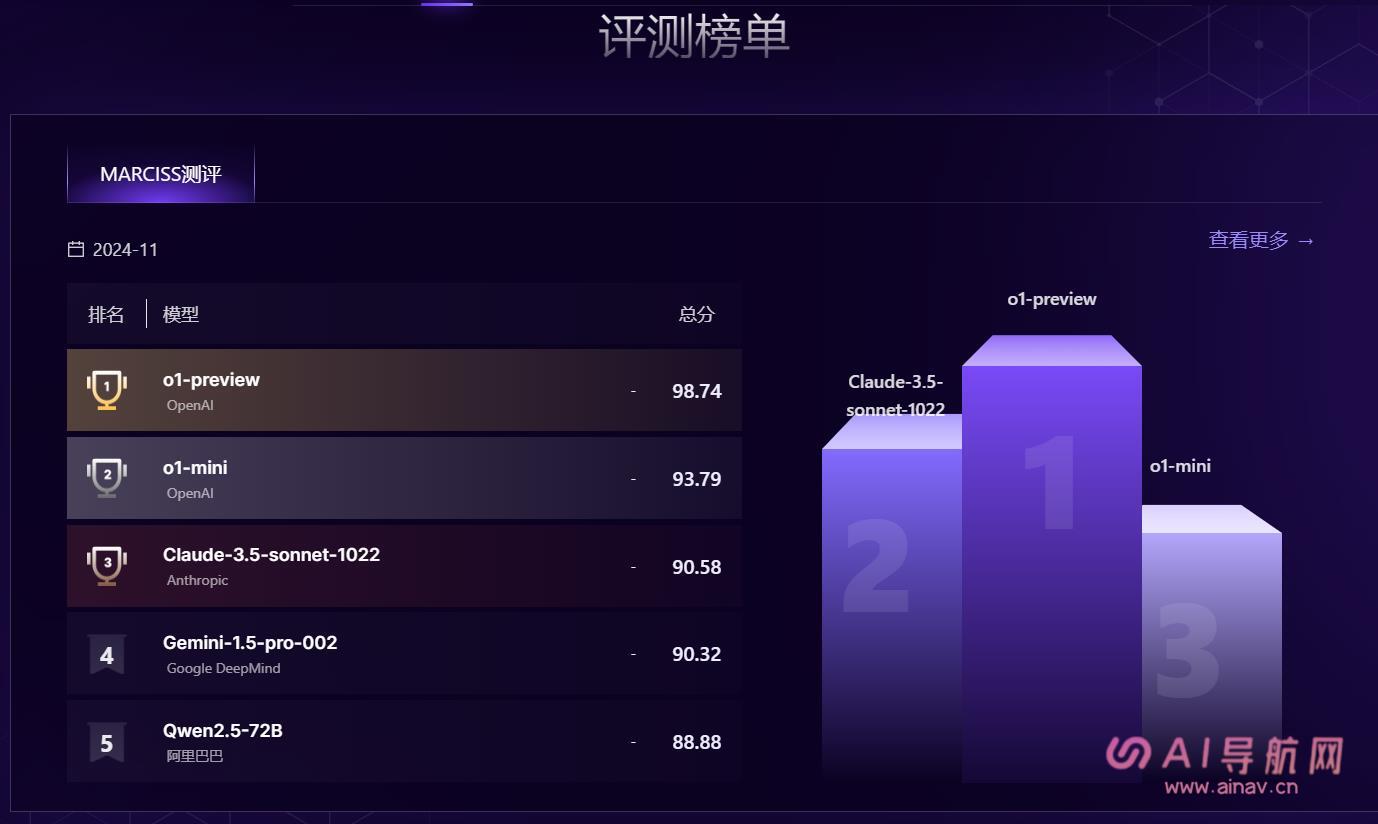
- 提供 MARCISS 测评等榜单,展示不同大模型的排名和总分情况。
- 如 2024 年 11 月的榜单中,OpenAI 的 o1-preview 模型以 98.74 分排名第一,o1-mini 模型以 93.79 分排名第二,Anthropic 的 Claude-3.5-sonnet-1022 模型以 90.58 分排名第三,Google DeepMind 的 Gemini-1.5-pro-002 模型以 90.32 分排名第四,阿里巴巴的 Qwen2.5-72B 模型以 88.88 分排名第五。
SuperBench 的其他介绍
- 团队背景与原则:SuperBench 团队依托在大模型领域多年的研究经验,基于公平、公正、公开的原则,构建了大模型评测框架。率先提出了五项大模型原生评测基准,并在此基础上不断进行丰富。
- 发布形式与优化:SuperBench 评测结果将会以双月级报告的形式对外发布,并且持续优化评测方法、补充新的测试数据,持续跟踪新的主流开源和闭源模型,促进大模型技术进步和产业落地。
- 四大优势:
- 开放性:SuperBench 评测数据集结合开源数据集与闭源数据集,后续版本将推出公开的验证集与封闭的测试集,既有助于模型优化,又防止刷题。
- 动态性:SuperBench 将定期发布评测结果与报告,每个周期刷新评测数据集的题目与类型,以避免静态考题导致的过拟合现象,可以有效防止作弊。
- 科学性:SuperBench 团队基于公平、公正、公开的原则,专门设计了一整套评测体系,包含五大原生评测基准,并在此基础上构建了 SuperBench 检测平台,研发了裁判模型 CritiqueLLM 等在内的自研评测算法,确保评测结果科学可靠。
- 权威性:SuperBench 由清华大学和中关村实验室联合发布,为独立的第三方非盈利性评测机构,评测体系公开透明,评测过程可追溯。
相关导航





暂无评论...