LiveBench 的介绍:
1. 核心目标与设计理念
LiveBench 的设计初衷是解决传统 LLM 基准测试中存在的局限性,如数据污染和主观性问题。它通过以下方式实现这一目标:
- 限制数据污染:LiveBench 每月发布新的问题集,并基于最近发布的数据集、arXiv 论文、新闻文章和 IMDb 电影简介设计问题,从而确保测试集的时效性和新颖性,减少数据泄露的可能性。
- 客观评分:所有问题都设有可验证的、客观的“基本真实答案”,评分过程完全自动化,无需依赖其他 LLM 作为评审员,确保评分的准确性和公正性。

2. 任务与分类
LiveBench 包含 6 大类共 18 项任务,涵盖多种能力领域,具体分类如下:
- 推理(Reasoning):涉及逻辑推理和复杂问题解决。
- 数学(Math):包括数学问题和逻辑推理。
- 编程(Coding):测试代码生成和编程能力。
- 语言(Language):评估语言理解和生成能力。
- 数据分析(Data Analysis):涉及数据处理和分析能力。
- 指令跟随(Instruction Following):测试模型对复杂指令的理解和执行能力。
3. 更新机制
为了保持基准测试的时效性和挑战性,LiveBench 每月更新问题集,并定期发布新的版本。例如:
- LiveBench-2024-06-24:初始版本。
- LiveBench-2024-07-26:新增编程问题和空间推理任务。
- LiveBench-2024-08-31:更新数学问题。
- LiveBench-2024-11-25:更新指令跟随问题,新增谜题和连接任务。
此外,LiveBench 会延迟公开最新版本的问题,以进一步减少数据污染的可能性。例如,LiveBench-2024-11-25 的 300 个新问题中有 30% 未公开。
4. 使用与参与
LiveBench 提供了详细的安装和使用指南,支持本地模型和 API 模型的评测。参与者可以通过以下方式使用 LiveBench:
- 安装:推荐使用虚拟环境进行安装,支持 Python 3.10。
- 运行评测:通过 Bash 脚本或 Python 脚本运行评测任务,支持并行化处理以加速评测过程。
- 结果展示:通过
show_livebench_result.py脚本查看模型的评测结果,并生成详细的分类和任务分析报告。
5. 权威性与影响力
LiveBench 由图灵奖得主 Yann LeCun 联合 Abacus.AI、纽约大学等机构推出,是目前生成式 AI 领域最权威的模型能力评测榜单之一。它通过创新的评测方法和严格的评分标准,推动了 LLM 的持续改进和社区参与。
6. 最新动态
2025.1.25日:
- DeepSeek的模型deepseek-r1上榜:DeepSeek的deepseek-r1,介于o1-2024-12-17模型和gemini-2.0-flash-thinking-exp-01-21模型之间
- 持续更新与改进:LiveBench 不断更新任务和评测标准,以适应 LLM 的快速发展。例如,LiveBench-2024-11-25 的更新增加了新的任务类型和更复杂的问题,进一步提升了评测的难度和挑战性。
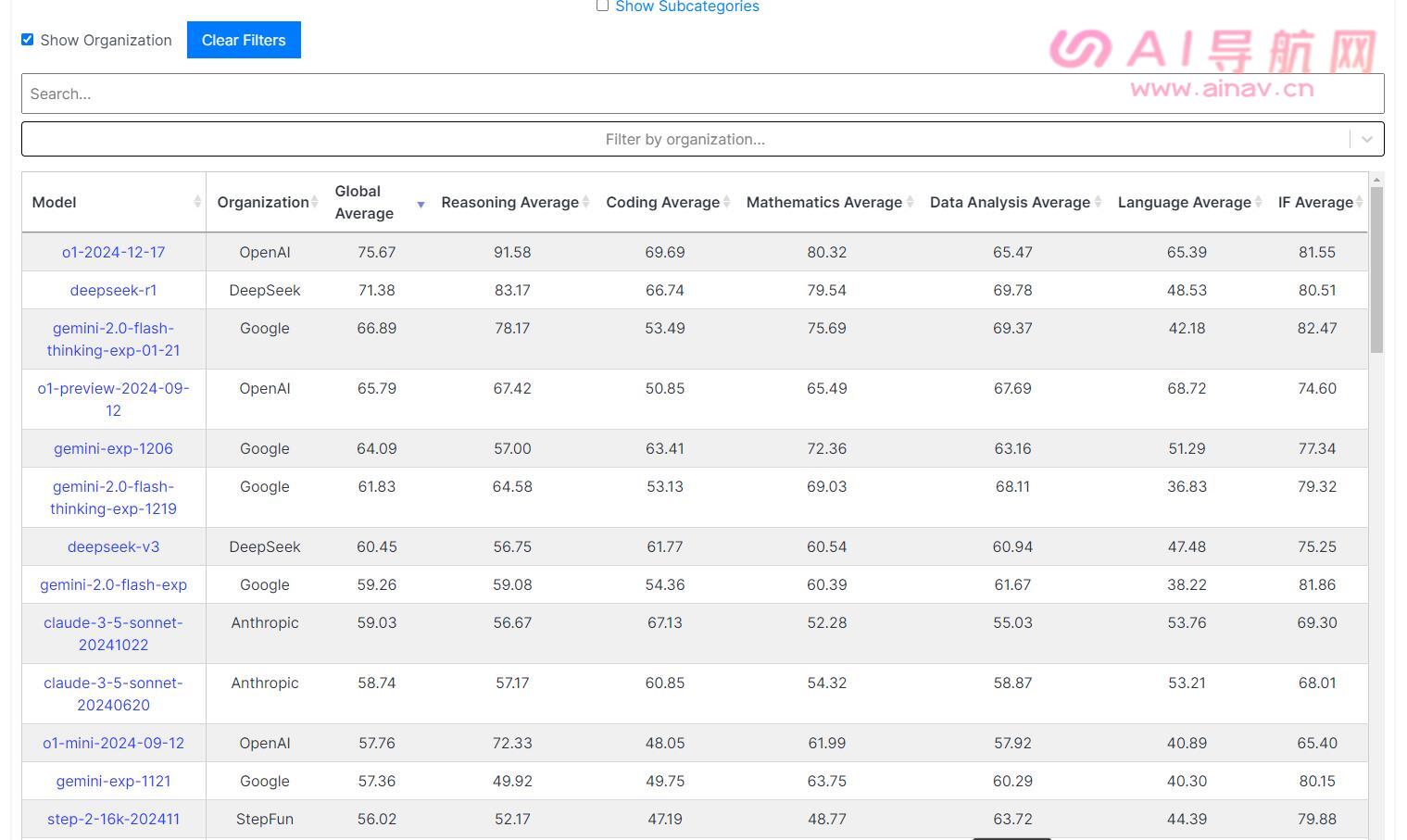
2025.1.25日,DeepSeek的模型deepseek-r1上榜Livebench平台
7. 未来展望
LiveBench 计划在未来继续扩展任务类型,增加更多领域的评测内容,并进一步优化评分机制,以保持其在 LLM 基准测试领域的领先地位。同时,LiveBench 也鼓励社区参与,支持开发者和研究人员提交新的问题和模型,共同推动 LLM 的发展。
8. 如何参与
- 提交问题:开发者可以创建自己的
question.jsonl文件,并按照 LiveBench 的格式要求提交新的评测任务。 - 提交模型:支持本地模型和 API 模型的评测,开发者可以通过
gen_model_answer.py或gen_api_answer.py脚本提交模型进行评测。 - 联系团队:通过 GitHub 提交 issue 或发送邮件至 livebench.ai@gmail.com,与 LiveBench 团队取得联系并获取支持。
相关链接:
https://livebench.ai/
https://github.com/LiveBench/LiveBench
相关导航




暂无评论...